Web Scraping in Python
Currently I am pursuing M Tech in Artificial intelligence and Machine Learning. As a developer, I possess expertise in an array of technologies ranging from Magento, Python, Artificial Intelligence and Machine Learning. My passion for technology and coding inspires me to continuously learn and innovate in my field.
With this blog, I aim to share my knowledge and experience with fellow developers in the community, helping them stay updated with the latest trends and techniques in the industry.
What is web scraping?
Web scraping is the process of extracting data from websites automatically using software. It involves parsing the HTML code of a website to identify specific data, such as product prices or customer reviews. Web scraping is important because it allows businesses and individuals to gather large amounts of data quickly and efficiently, which can be used for market research, competitor analysis, price monitoring, and many other purposes.
Python is a popular language for web scraping for several reasons. Firstly, it has many libraries and frameworks that make web scraping easy and efficient, such as BeautifulSoup and Scrapy. These libraries provide powerful tools for parsing HTML and extracting data from web pages, making it easy to write code that scrapes data quickly and accurately.
Secondly, Python is a versatile language that is easy to learn and use. Its syntax is simple and readable, and it can be used for a wide range of applications beyond web scraping. This makes it a popular choice for developers.
Ethics and Legal Considerations
In web scraping, it's important to understand the legality of web scraping in your jurisdiction, obtain permission from website owners before collecting their data, and to use collected data responsibly and ethically. It is essential to respect the rights of website owners and users and to avoid collecting data without permission or in a way that violates privacy. Being aware of the ethical and legal considerations of web scraping is important to conduct yourself responsibly and ethically while using this technology.
Let's learn how to write Python code to scrap websites in Python.
Install Python Libraries
In this tutorial, I am going to use the following 3 libraries for web scraping:
requests: This library is used for sending HTTP requests to websites and retrieving the responses.
lxml: It is a library that is used to parse and process XML and HTML documents in a fast and efficient way.
bs4: The bs4 library allows you to search for specific HTML tags, extract their attributes and contents, and navigate through the structure of the HTML or XML document, enabling you to extract relevant data and information for use in your Python programs or data analysis projects.
Run the following commands in your terminal to install these libraries using pip
pip install requests
pip install lxml
pip install bs4
Sample website for scraping
You can use your own website/projects for scraping and testing all these commands. Here I will be using https://toscrape.com/ which is provided basically for scraping and testing purposes. This website has 2 sub-websites that you can use for writing your scraping code
I will be using http://books.toscrape.com/ in this tutorial for code explanation.
Understanding / Identifying the section of the website to scrap
The website that we want to scrap looks like the below image

First of all, identify the section of the page which you want to scrap. Then check the HTML document tags of that section which you want to scrap and then you can use tags, CSS classes or ids to get the data from those sections.
You can right-click on the section of the content and click on "Inspect" to see the HTML code and tag of that section that you want to grab. For example, I have selected a section where "We love being scraped!" text is written and I can see HTML code like below:

Code Examples
Let's say you want to grab the content "We love being scraped!" and as shown in the above image it is inside <small> tag. Here is the code to grab this content
# Import required libraries
import requests
import bs4
# Prapare the url of the website which you want to scrap
url_to_scrap = "http://books.toscrape.com/";
# Make http request the url and get the response from the website
result = requests.get(url_to_scrap)
# result.text contains HTML of the page
# lxml parser is used to parse the HTML code here
soup = bs4.BeautifulSoup(result.text, "lxml")
# Get the content of the tag small.
# It will return a list of all matched content with tag <small> in the HMTL code
small_titles = soup.select('small')
print(small_titles)
# Now you can loop through each matching item of the list or grab the first item of the list
for title in small_titles:
# Check type of title variable. You will see title is of a bs4 element tag type here
print(type(title))
#. To get the actual text inside the title use .text or getText()
print(title.text)
Once you run this code you will see the following output:

If you can see this output. Congratulations. You have successfully executed your first web scraping script.
Moving on, when you click next button at the bottom of the page http://books.toscrape.com/ you will see dynamic page id in the URL like http://books.toscrape.com/catalogue/page-2.html .
Now let's say you have the following client requirement:
I want a Python dictionary of all the products from page 1 to page 5. The key of the dictionary will be the name of the product and value will be the price of the product.
If you inspect the HTML code of one product on the page you will see HTML code like below
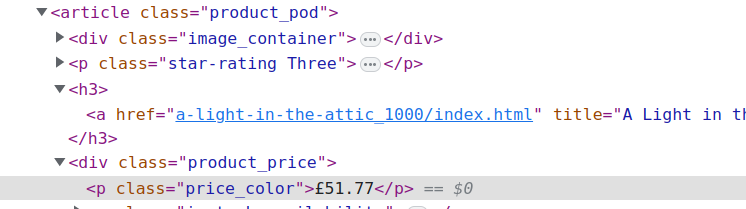
Now there are different ways to get the product title from HTML code. In the above example, you see the product title is inside a <h3><a> tag of the product_pod class. Also, we can see that the product price is wrapped in a <p> tag inside the CSS class product_price.
soup allows us to select HTMl content using classes also. For example to get all content of the elements will class product_pod we need to use code soup.select('.product_pod') . It will give us a list of all the elements in product_pod class and then we can loop through it to get the desired inner element like title or price.
Here is the complete code to prepare the dictionary with the books name and price:
Once you execute the code you will see the output which contains the book's title and their prices like the below image

This is a great step. Now you can go ahead and start exploring web scraping on your own. On this book's website, you can see that book reviews are also present and as an assignment, you can go ahead and extract the book title and their review in a dictionary format.